


In this month’s issue:
Semi-supervised takes a casual approach to the causal by proposing some new conventions for causal diagrams.
The simple pleasures of a big fat textbook in the white stuff.
The dunghill champions the over-thinker.
Plus first steps into Rust, the RSS makes a smart move, and how I’m talking more than I’m typing.

Semi-supervised
I'm going to share with you my own take on causality diagrams. These are not the hardcore DAG diagrams used by Judea Pearl and others to plan causal experiments. Although they might lead in that direction. No, these are rough and ready diagrams designed to simplify and clarify problems at the early stages.
They were born partly out of frustration: I found that most textbook examples of causal diagrams were for simple, straightforward cases where the nodes represent discrete events that happen in sequence. The “smoke, fire alarm” example is perfect for explaining causality concepts, but quite unrepresentative of some very typical causal chains. For example, the weather clearly affects many aspects of human behaviour, but - except for in the canonical rain/umbrella example - the effect is usually ongoing rather than sequential. While the sun is shining, I continue my walk in the park.
So this is one thing I’d like to recognise in a causal diagram: whether a causal effect is sequential or ongoing. Another thing is whether the cause is a necessary condition, a sufficient condition, both1 or neither (which in most cases means it is an insufficient, but necessary part of an unnecessary but sufficient condition - INUS for short. A small headache but worth looking up!) For general problem solving, it is useful to consider whether one thing must happen to produce an effect, just as it is useful to consider whether it is sufficient by itself to produce that effect.
Lastly, since these causal diagrams are simply aids to thinking, and not inputs into some further process, there’s no reason why they need to be either directed or acyclic, so I’m happy to have arrows going both ways and edges that form loops.
So the conventions I’ve adopted for my causal graphs are:
Dotted lines for an ongoing effect, full lines for a sequential effect
Tail arrowheads that denote the type of condition:
Circle = necessary
Square = sufficient
Diamond = necessary and sufficient
None = neither necessary nor sufficient
Here is an example showing the causes of product purchase. It’s somewhat simplified and a bit generic as it’s part of some Coppelia training material (incidentally, if you or your company are interested in training, then do get in touch) but it does the job, that is it brings out the complexity of the problem.
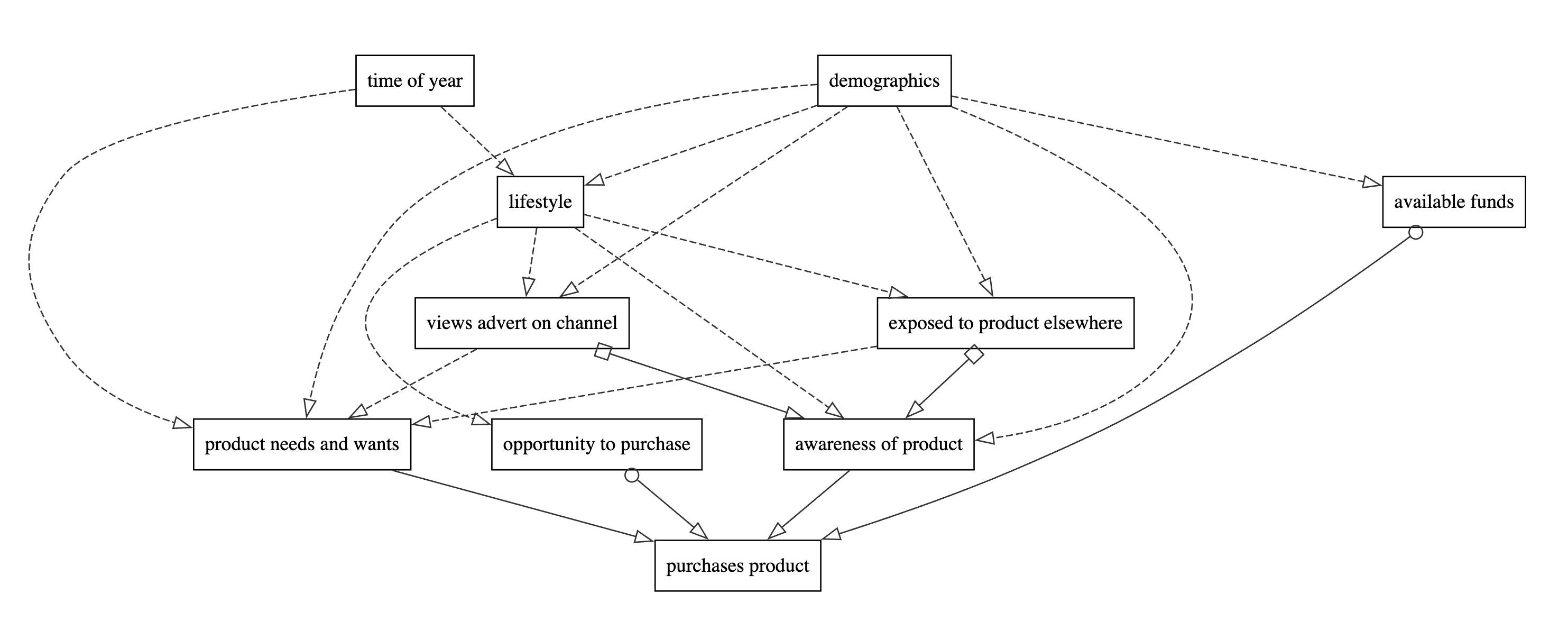
Note, I’ve resorted to Graphviz for this diagram as Mermaid isn’t quite up to the level of customisation needed. Code can be found here. Dump it in something like this to play with it.
Finally, some tips on construction:
Check for causality: Deciding whether or not a causal relationship exists between two nodes can be quite challenging, especially when the causal relationship is ongoing. My trick is to imagine that I’m a time-travelling, omnipotent being who can rewind time, tinker with reality and and then re-run things to see how they would have turned out. According to the counterfactual definition of causality, if my change to A makes no difference to B, then A has no causal effect on B. This seems to work too for ongoing causes like demographic attributes: as an omnipotent being, I can swoop in and substitute an older population for a younger one while holding everything else more or less constant.
Make pragmatic simplifications: the goal is to create a general picture of the causal relationships that will help you think through a problem. Not every detail is necessary. In particular you can collapse nodes (I could have added a separate node for gender, age, income etc in the graph above but that would have simply created duplicate causal pathways without adding anything useful to the picture) and collapse chains (I could have spelt out all the ways in which a person’s lifestyle effects the probability that a person is exposed to an advert but the result would have been an unhelpful spaghetti).
Don’t sweat the edge cases: Yes, strictly speaking you can be exposed to an advert and remain mercifully unaware of the product, so yes, strictly speaking, “views advert” is not a sufficient cause for “awareness of product”. But in the vast majority of cases, if the product is directly advertised, it is sufficient. Usually that’s good enough for me.
Anyway, the diagram and the notation are works in progress. If you have any thoughts, criticisms, or suggestions for improvement, I would love to hear them!
Please do send me your questions and work dilemmas. You can DM me on Substack or email me at simon@coppelia.io.

The white stuff
There's something particularly satisfying about reading a general textbook on a topic for which you already have a deep but very patchy knowledge. For example, this month I've started reading Learning the Bash Shell by Cameron Newham. Now if I hadn’t spent twenty-five years hacking my way through shell scripts, this would have been an ordeal. But, as it is, it's full of surprisingly pleasurable “Oh that’s why” moments. And, having sunk so much time into this topic (through no fault of my own), I can’t but help care about the content.
It seems to me that the value of a broad, discipline-level textbook is even greater now that we can go so deep, so quickly online, without ever seeing how the pieces fit together. The limited physical nature of the textbook is also important. You just can’t go down a rabbit hole. It forces you into a breadth-first rather than a depth-first search. And a broad view of a discipline inevitably helps with impostor syndrome. We are naturally less paranoid once we know the terrain.
So with that in mind, here are three of my favourites. I think of them as a sort of polyfilla that, when spread evenly, will fill in the gaps in your knowledge.
Computer Science: An Overview by Glenn Brookshear - Broad and beautiful, it saved me when I landed in a proper IT department.
Economics by David Begg - Stopped me from feeling like a complete fraud in the company of economists.
Artificial Intelligence: A Modern Approach by Russell and Norvig - Mentioned so often before on this substack, but I'll never tire of promoting it as the perfect antidote to a narrow focus on LLMs.
Although it's hardly work-related, I've also got to mention Biology: A Global Approach by Neil Campbell et al, since it is one of the most awe-inspiring textbooks of all time, covering modern biology from atoms to the human mind. It's also excellent for raising your monitor.

The dunghill
Certain phrases still trigger early career PTSD. A particular horror is “You’re overthinking it.” I wince when I hear it, especially delivered in a pompous, strident tone by someone who has not thought about it at all. Let me break down the reasons why this particular phrase bugs me so.
First, there's a hidden premise: All problems and ideas can be reduced with enough worldly brilliance to something simple and pithy. If they're not in this final state, then there's still work to be done. Go away and try again. The irreducibly complex simply does not exist in the practical, no-nonsense world of the executive.
Second, there is an implied value judgement: It relies on the stereotype of the befuddled nerd who can't see the wood for the trees. You’re overthinking it is the slap which wakes them from their academic, that is to say, largely useless, reveries.
Third, it's a power move: The unsaid part is, “There's nothing I don't know that's worth understanding. I have no intention of meeting you in the middle. Play it back to me in my language.”
Fourth, it's absurd: You were hired to overthink it. It's your job to consider all the various ways in which something might not be right, all the little things that might go wrong with catastrophic results. You were recruited on the strength of years of overthinking. Yes, solutions can be simple, but problems are usually complex. That's why they are problems.
A more charitable interpretation of the situation is that "you're overthinking it" is simply shorthand for “You're giving me too many details. I'm only interested in the conclusions, the parts that affect my decision”. But that's not what “overthinking” means. If that was the intent, then I offer this more respectful alternative:
Please continue to think about this in great depth, and then present me with your conclusions—and, if I should so ask, your methods.
That would be nice.
If you have some particularly noxious bullshit that you would like to share then I’d love to hear from you. DM me on substack or email me at simon@coppelia.io.
From Coppelia
I’ve started to learn Rust - I can’t say it’s motivated by anything more than curiosity (at the zeal of the Rustaceans), awe at the speed of packages like polars and uv, and a growing dissatisfaction with the messiness of Python. I’ll let you know how I get on.
In
excellent substack (subscribe if you haven’t already). I read that the Royal Statistical Society has launched a peer-reviewed data science and AI journal. This feels like the right direction for the RSS. They have a reputation for rigour, and they can bring that to the table.Meanwhile on my to-do list for GenAI are:
Check out Firebase (thanks to Wendy Martinez for the nudge)
Read up on AlphaEvolve (evolutionary algorithms and LLMs are intuitively a good match).
Finally, last month I mentioned Willow, an AI-based dictation tool. I'm taken aback by just how much this has changed my working life. I’d say more than half my text output is now dictated. Thanks again to
!
If you’ve enjoyed this newsletter or have any other feedback, please leave a comment.
Rare, since if this is the case, then it's often best just to merge the nodes.