


In this month’s issue:
As the government announces that it is considering using machine learning to estimate the age of asylum seekers, the dunghill calls for transparency about trade-offs.
Semi-supervised talks up the virtues of a good old-fashioned analogy.
We take a look at some of the beautiful, extravagant, but ultimately doomed attempts to communicate the inner workings of AI in the white stuff.
Plus more synthetic respondent lunacy, my continuing adventures in Rust, and yet another concept diagram.

Semi-supervised
A final, for now, tip for solving complex problems in data science. I don't have a name for this technique, except perhaps “domain-switching”, or “working with an analogy”. And anyway, it would be rather presumptuous to name it, since it's as old as the hills. Nevertheless, it is rarely identified explicitly; and I have yet to see its virtues spelt out in a way that does it justice. I'm talking about the following process: faced with a difficult problem - one with many moving parts, full of unknowns and uncertainties - we identify the equivalent problem in a completely different domain and try to solve it there.
An obvious example is the transfer of a business problem to its equivalent in medicine: customers become patients, marketing campaigns become medical trials, behaviours become symptoms, etc. We are encouraged in this direction because so much of statistics was originally developed to solve medical problems, and so the language of treatment,1 trials and control suggests this possibility. Traditional statistics hints at many other potentially fruitful problem transfers: Games (guessing games, card games, games with dice, strategy games) are an ever-useful domain in which to recast your problem. The probabilist’s urn full of coloured pebbles will help ground many a mind-bending probability scenario. I often shift my problems to idealised laboratories or to fields of crops (a hangover from 50s stats textbooks). I have others that are a bit more unusual: cookery, robots, space probes, village shops, plagues.
But why does it work? What’s in an analogy? I think at least four useful things happen when you switch domain:
First, it forces you to think about which features of the real world are important for solving the problem, since these are the features that will need an equivalent in the new domain. Using the language of a previous post, it forces you to sort out your ontology.
Second, it gets your thinking out of a rut. Your previous attempts to solve the problem in the original domain have been hampered by assumptions that you didn’t know you were making but which show up as optional in the new domain. Plus the analogous objects in the new domain may have ways of interacting which weren’t at all obvious in the old one. Even the differences between the two domains can be enlightening. Perhaps you are thinking of customer subscriptions as though they were human lifespans (to make use of survival models from medicine and insurance), but think carefully: a customer can disappear for a while and then resubscribe. Does your survival model handle resurrections?
Third, it takes you towards an understanding of your problem in the abstract but without leaving behind the concrete. Perhaps your problem is hard because it involves some tricky features: feedback loops, an exploding number of dimensions, counterintuitive concepts from probability, to name just a few. Stepping straight into such difficult terrain, you can easily get lost, but by considering the problem first in a new domain, you can start to understand these abstractions as the things that the two scenarios have in common.
Finally, it is invaluable for explaining ideas and for joint problem-solving. Take the situation I described in last month’s dunghill - in which you are accused of overthinking a problem. The frustrated client cannot see the issue you are raising, probably because of one of you is making an undeclared assumption. When the problem is transferred to another domain, not only is it neutral territory (so everyone can calm down a bit!), but both of you are forced to explain what you assumed was obvious, as you spell out what the problem now looks like.
Of course the topic of the hour is problem-solving with large language models, and in particular explaining where we think they will work, and where not, and why. I’m still working on alternative domains for that one - any suggestions are most welcome.
Please do send me your questions and work dilemmas. You can DM me on substack or email me at simon@coppelia.io.

The white stuff
Not your conventional white papers this month, but rather two very similar and equally beautiful attempts to go beyond paper and explore the interactive possibilities of the browser. Distil was a short-lived, peer-reviewed online journal “founded as an adapter between traditional and online scientific publishing”. Eventually, the burden of producing these stunning interactive articles proved too much, and they shut down in July 2021. The droplet logo now looks more like a teardrop, and the farewell post is very sad. The articles are still there though and are well worth exploring. I particularly enjoyed A Visual Exploration of Gaussian Processes.
Still going, probably because of infinite funding, are the explorables produced by Pair, a collaborative team of developers and designers within Google. These are, I think, the same people who produced my all-time favourite: the neural network playground. (I honestly believe you could replace a day's training on deep learning with a couple of hours alone with this visualisation.) Again, some of the articles are old (by which I mean three or four years!), but this hardly matters when the last five years have been about scale. I like this one in particular.

The dunghill
It was reported in The Guardian last week that the government is considering using an AI (by which it means the kind of algorithm that for decades went by the more modest name of ‘machine learning classifier’) to verify the ages of child asylum seekers. Now, I don't know if this is a good idea, but what I do know - since it is almost inevitable - is that the solution will be mis-sold on the strength of its overall accuracy. How do I know this?
The proposed solution, says the immigration minister, Angela Eagle, will involve an algorithm “trained on millions of images where an individual’s age is verifiable”. The resulting “facial age estimation” tool will then be used in borderline cases to predict whether an asylum seeker is under 18. If this is the case, then there are two ways in which this classifier could get things wrong: it could classify an individual as a child (i.e. as under 18) when they are not (a false positive); or it could fail to classify an individual as a child when they are (a false negative). The two errors have very different consequences (or costs, as we would say in the machine learning world). In the first case, a person might undeservedly receive the treatment reserved for an unaccompanied minor (the expense of providing foster care, education and safe-guarding for an unaccompanied minor is, I understand, many times the cost of housing an adult) and contributing, in the long run, to the erosion of trust in the asylum system. In the second case, the state will have failed in its duty to protect a vulnerable child. These two types of error are related. For any given classifier, we can minimise the number of false positives but only at the expense of creating more false negatives. In our case, we can set the “facial age” classifier so that more of those falsely claiming to be children are identified, but only at the cost of rejecting a greater number of genuine claims.
Now comes the part that will surprise most people who do not work in machine learning. The threshold for this tradeoff is almost always set subjectively, during the training of the classifier, as the desired balance between precision (measuring the number of false positives) and recall (measuring the number of false negatives). This means that someone, somewhere, will need to decide how to balance the harm caused to a child misidentified as an adult against the cost incurred when one person abuses the asylum system -an unenviable task for anyone with a conscience2, and one that is both political and likely to be made under pressure to deliver on promises or contracts.
Of course we wouldn’t have to trade off false positives and false negatives at all if our classifier were perfect, and the name of the game is to improve classifiers so that less of a trade-off needs to be made. But in almost all scenarios, a perfect classifier is not going to happen, since the decision-making environment is, in the language of a previous post, stochastic and partially observable.3 Trade-offs cannot be eliminated by just working harder. And this is obviously true in our case: a person’s face is only part of the information needed to work out their age, and presumably quite an unreliable part at that (would extreme trauma not prematurely age a face?) No amount of training and tinkering with the algorithm is going to change this.
And so the question is: will anyone go to the trouble of explaining the above to all those charities, government departments, and ministers who have a stake in the asylum process, let alone to the general public? Or will they do what happens almost always in the business world - simply present the total number of errors (false positives and negatives) as a percentage of all cases and call its complement accuracy? Worst of all, and I hope this would never happen, might they present the classifier’s success at minimising the false positives (in catching the bad guys) as the whole story? In the last two scenarios, the trade-off, as well as its subjective and possibly political nature, has been successfully buried.
This is what I meant when I said that I was certain that the “facial age” classifier would be mis-sold on the strength of its overall accuracy. I meant that the false-positive, false-negative trade-off will rarely feature in discussions about the classifier’s efficacy. Instead everyone will talk about its accuracy - a single metric - as though it were the most unproblematic of concepts. This is based on several decades of accumulated pessimism. Once again it would be nice if I were proved wrong.
If you have some particularly noxious bullshit that you would like to share then I’d love to hear from you. DM me on substack or email me at simon@coppelia.io.
From Coppelia
I’ve been trying to forget about synthetic respondents and was hoping that last month’s dunghill would release me. But it’s difficult when readers keep sending me such jaw-dropping examples. This one, passed to me by an brilliant data scientist working in the world of advertising, is a beauty, and has to be read to be believed. In response, it’s hard to know how to say this any more clearly: The notoriously difficult-to-find high-net-worth audience are not spending their precious time blogging - i.e. creating training data for LLMs - for the same reasons they are not attending agency focus groups. But I can tell you who is right now filling the internet with talk about difficult-to-find high-net-worth individuals… think about it!
The same person who alerted me to this article also supplied a nice diagram for this process:
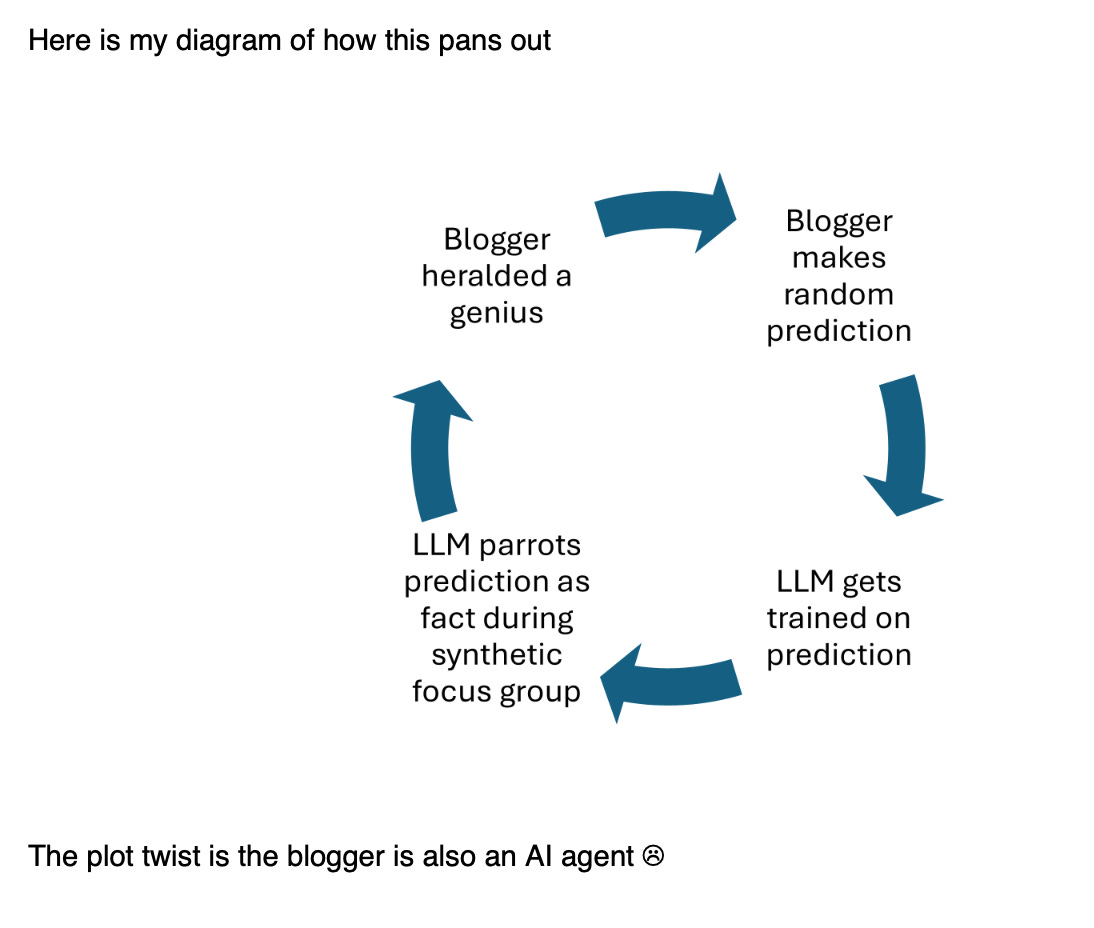
As another reader pointed out, this further plot twist - dystopia or utopia, depending on your point of view - was explored in an interesting article in Nature: AI models collapse when trained on recursively generated data.
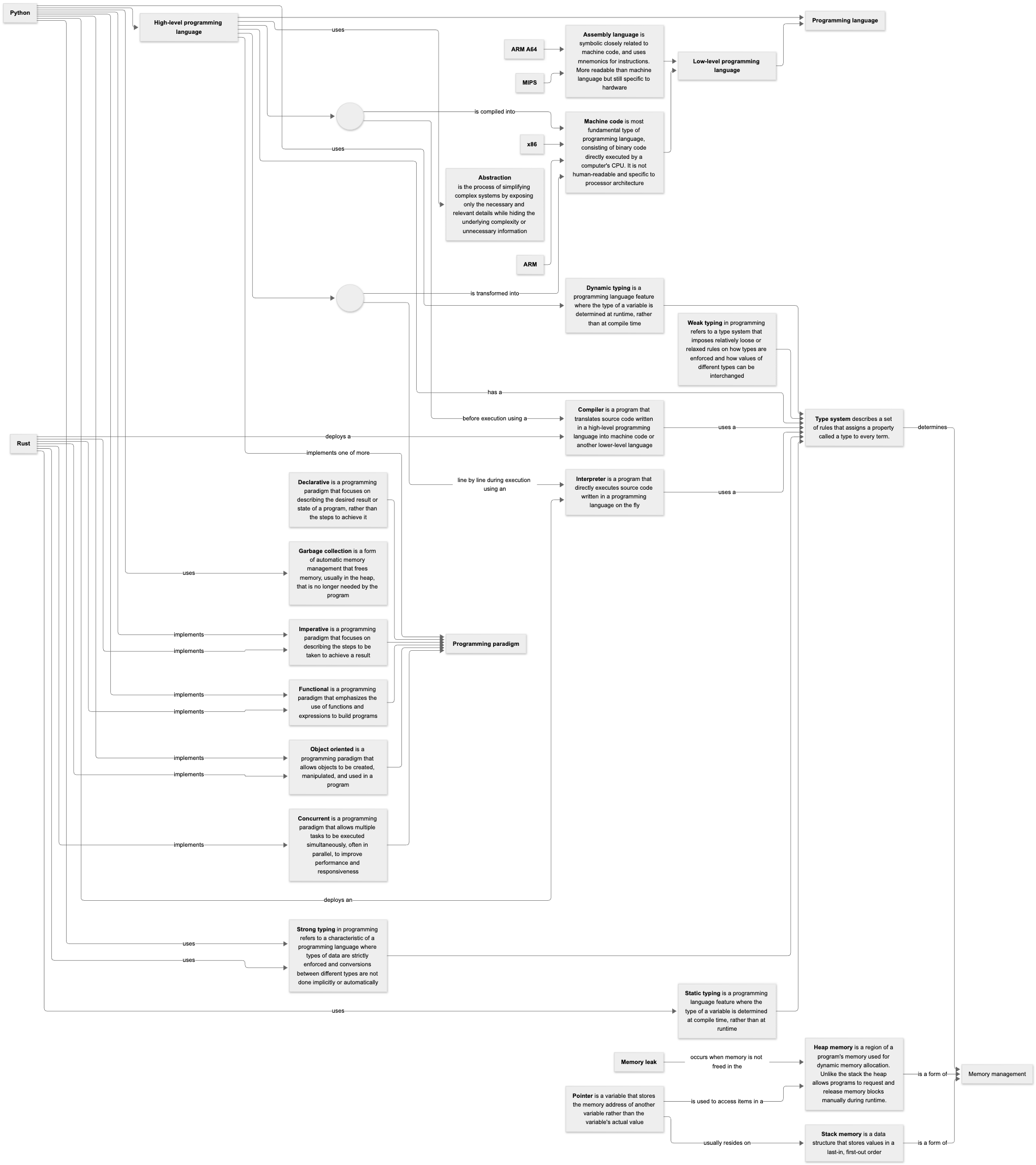
Meanwhile I’m still exploring Rust as a complementary language to Python for data science. If nothing else, its strict attention to memory management and error handling should make me a better overall programmer. A promising direction is indicated by its interoperability (not a word I've used before), especially when it comes to Python. In other words, it's very easy to produce Python wrappers for Rust packages, which opens up the possibility of using Python for scripting and prototyping, while bracketing off modules that require speed and reliability for implementation Rust. I'll let you know.
In the meantime, here’s a concept diagram I recently produced for a client, explaining how Rust and Python differ as programming languages.
If you’ve enjoyed this newsletter or have any other feedback, please leave a comment.
Although I think perhaps “treatment” came from agricultural examples.
Incidentally, another argument against the automation of life-changing decisions is that a person making such a decision at least carries the burden of a conscience.
And this is true not just of machine leaning classifiers, but also of all the government institutions and processes that are in the business of making what are inevitably flawed classifications. These systems can be improved but never to the point of eliminating a trade off. Despite this we are always demanding that both types of error be brought down to zero- as though it were possible to catch every plotting terrorist without incarcerating almost the entire population, or prevent every violent attack by a released prisoner without locking the entire prison population up for life, or avoid every horrific example of child abuse without breaking up families on the slightest suspicion.